
Docker在1.9版本中引入了一整套的自定义网络命令和跨主机网络支持。这是libnetwork项目从Docker的主仓库抽离之后的一次重大变化。不论你是否已经注意到了,Docker的网络新特性即将对用户的习惯产生十分明显的改变。
libnetwork和Docker网络
libnetwork项目从lincontainer和Docker代码的分离早在Docker 1.7版本就已经完成了(从Docker 1.6版本的网络代码中抽离)。在此之后,容器的网络接口就成为了一个个可替换的插件模块。由于这次变化进行的十分平顺,作为Docker的使用者几乎不会感觉到其中的差异,然而这个改变为接下来的一系列扩展埋下了很好的伏笔。
概括来说,libnetwork所做的最核心事情是定义了一组标准的容器网络模型(Container Network Model,简称CNM),只要符合这个模型的网络接口就能被用于容器之间通信,而通信的过程和细节可以完全由网络接口来实现。
Docker的容器网络模型最初是由思科公司员工Erik提出的设想,比较有趣的是Erik本人并不是Docker和libnetwork代码的直接贡献者。最初Erik只是为了扩展Docker网络方面的能力,设计了一个Docker网桥的扩展原型,并将这个思路反馈给了Docker社区。然而他的大胆设想得到了Docker团队的认同,并在与Docker的其他合作伙伴广泛讨论之后,逐渐形成了libnetwork的雏形。
在这个网络模型中定义了三个的术语:Sandbox、Endpoint和Network。
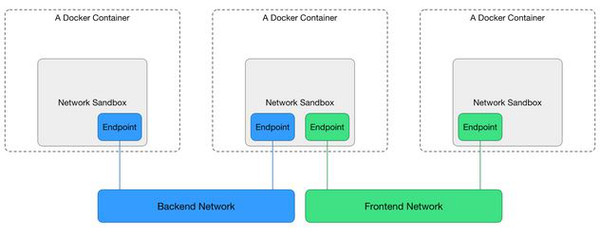
如上图所示,它们分别是容器通信中『容器网络环境』、『容器虚拟网卡』和『主机虚拟网卡/网桥』的抽象。
Sandbox:对应一个容器中的网络环境,包括相应的网卡配置、路由表、DNS配置等。CNM很形象的将它表示为网络的『沙盒』,因为这样的网络环境是随着容器的创建而创建,又随着容器销毁而不复存在的; Endpoint:实际上就是一个容器中的虚拟网卡,在容器中会显示为eth0、eth1依次类推;
Network:指的是一个能够相互通信的容器网络,加入了同一个网络的容器直接可以直接通过对方的名字相互连接。它的实体本质上是主机上的虚拟网卡或网桥。
这种抽象为Docker的1.7版本带来了十分平滑的过渡,除了文档中的三种经典『网络模式』被换成了『网络插件』,用户几乎感觉不到使用起来的差异。
直到1.9版本的到来,Docker终于将网络的控制能力完全开放给了终端用户,并因此改变了连接两个容器通信的操作方式(当然,Docker为兼容性做足了功夫,所以即便你不知道下面所有的这些差异点,仍然丝毫不会影响继续用过去的方式使用Docker)。
Docker 1.9中网络相关的变化集中体现在新的『docker network』命令上。
$ docker network –help Usage: docker network [OPTIONS]COMMAND [OPTIONS] Commands: ls List all networks rm Remove a network create Create a network connect Connect container to anetwork disconnect Disconnect container from anetwork inspect Display detailed networkinformation
简单介绍一下这些命令的作用。
1、docker network ls
这个命令用于列出所有当前主机上或Swarm集群上的网络:
$ docker network ls NETWORK ID NAME DRIVER SCOPE 111b61f9844b backend bridge local 50de367459f9 bridge bridge local a1f6fdc7da5f frontend bridge local b8c0ed2202df host host local 87aa20ea95b1 none null local
在默认情况下会看到三个网络,它们是Docker Deamon进程创建的。它们实际上分别对应了Docker过去的三种『网络模式』:
- bridge:容器使用独立网络Namespace,并连接到docker0虚拟网卡(默认模式)
- none:容器没有任何网卡,适合不需要与外部通过网络通信的容器
- host:容器与主机共享网络Namespace,拥有与主机相同的网络设备
在引入libnetwork后,它们不再是固定的『网络模式』了,而只是三种不同『网络插件』的实体。说它们是实体,是因为现在用户可以利用Docker的网络命令创建更多与默认网络相似的网络,每一个都是特定类型网络插件的实体。
02、docker network create / docker network rm
这两个命令用于新建或删除一个容器网络,创建时可以用『–driver』参数使用的网络插件,例如:
$ docker network create --driver=bridge frontend b6942f95d04ac2f0ba7c80016eabdbce3739e4dc4abd6d3824a47348c4ef9e54
现在这个主机上有了一个新的bridge类型的Docker网络:
$ docker network ls NETWORK ID NAME DRIVER SCOPE 111b61f9844b backend bridge local 50de367459f9 bridge bridge local a1f6fdc7da5f frontend bridge local b8c0ed2202df host host local 87aa20ea95b1 none null local .........
Docker容器可以在创建时通过『–net』参数指定所使用的网络,连接到同一个网络的容器可以直接相互通信。
当一个容器网络不再需要时,可以将它删除:
$ docker network rm frontend
03、docker network connect / docker network disconnect
这两个命令用于动态的将容器添加进一个已有网络,或将容器从网络中移除。为了比较清楚的说明这一点,我们来看一个例子。
参照前面的libnetwork容器网络模型示意图中的情形创建两个网络:
$ docker network create --subnet=192.168.10.0/24 br10 $ docker network create --subnet=192.168.20.0/24 br20
然后运行三个容器,让第一个容器接入frontend网络,第二个容器同时接入两个网络,三个容器只接入backend网络。首先用『–net』参数可以很容易创建出第一和第三个容器:
docker create -i --net=br10 --name=ins01 --ip=192.168.10.100 centos7.3:v1 docker create -i --net=br20 --name=ins03 --ip=192.168.20.100 centos7.3:v1
如何创建一个同时加入两个网络的容器呢?由于创建容器时的『–net』参数只能指定一个网络名称,因此需要在创建过后再用docker network connect命令添加另一个网络:
docker create -i --net=br10 --name=ins02 --ip=192.168.10.200 centos7.3:v1 docker network connect --ip 192.168.20.200 br20 ins02
启动 ins01、ins02、ins03三个容器
docker start ins01 ins02 ins03
现在通过ping命令测试一下这几个容器之间的连通性:
$ docker exec -it ins01 ping ins02 #可以ping通 $ docker exec -it ins01 ping ins03 #找不到名称为ins03的容器 $ docker exec -it ins02 ping ins01 #可以ping通 $ docker exec -it ins02 ping ins03 #可以ping通 $ docker exec -it ins03 ping ins01 #找不到名称为ins01的容器 $ docker exec -it ins03 ping ins02 #可以ping通
这个结果也证实了在相同网络中的两个容器可以直接使用名称相互找到对方,而在不同网络中的容器直接是不能够直接通信的。此时还可以通过docker networkdisconnect动态的将指定容器从指定的网络中移除:
$ docker network disconnect br20 ins02 $ docker exec -it ins02 ping ins03 #找不到名称为ins03的容器
可见,将ins02容器实例从backend网络中移除后,它就不能直接连通ins03容器实例了。
04、docker network inspect
最后这个命令可以用来显示指定容器网络的信息,以及所有连接到这个网络中的容器列表:
$ docker network inspect br10
[
{
"Name": "br10",
"Id": "5f56ccd1ce3996017439a8a180e03b2be2b7a12503140e38e64ae32305df9983",
"Created": "2017-07-04T10:54:48.341223344Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "192.168.10.0/24"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"Containers": {
"05a6b63a26bf114b38de94d58e53d2123920b31e54c7451b3d46e6a1884e7c6d": {
"Name": "ins01",
"EndpointID": "594e9f91fa9319a1be069a38e3ebd10dcbf3c3d0fe5a6edf6b0e3808baad833d",
"MacAddress": "02:42:c0:a8:0a:64",
"IPv4Address": "192.168.10.100/24",
"IPv6Address": ""
},
"d705c6958a59991951be79747348672bce3aed69d955f47fcb82eb50ad55cc02": {
"Name": "ins02",
"EndpointID": "d2e46d96cd49020426079af6be5d323ac84e72c4c966fefcf6af4531fe8cba25",
"MacAddress": "02:42:c0:a8:0a:c8",
"IPv4Address": "192.168.10.200/24",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
值得指出的是,同一主机上的每个不同网络分别拥有不同的网络地址段,因此同时属于多个网络的容器会有多个虚拟网卡和多个IP地址。
由此可以看出,libnetwork带来的最直观变化实际上是:docker0不再是唯一的容器网络了,用户可以创建任意多个与docker0相似的网络来隔离容器之间的通信。然而,要仔细来说,用户自定义的网络和默认网络还是有不一样的地方。
默认的三个网络是不能被删除的,而用户自定义的网络可以用『docker networkrm』命令删掉; 连接到默认的bridge网络连接的容器需要明确的在启动时使用『–link』参数相互指定,才能在容器里使用容器名称连接到对方。而连接到自定义网络的容器,不需要任何配置就可以直接使用容器名连接到任何一个属于同一网络中的容器。这样的设计即方便了容器之间进行通信,又能够有效限制通信范围,增加网络安全性;在Docker 1.9文档中已经明确指出, 不再推荐容器使用默认的bridge网卡,它的存在仅仅是为了兼容早期设计。而容器间的『–link』通信方式也已经被标记为『过时的』功能,并可能会在将来的某个版本中被彻底移除。Docker的内置Overlay网络
内置跨主机的网络通信一直是Docker备受期待的功能,在1.9版本之前,社区中就已经有许多第三方的工具或方法尝试解决这个问题,例如Macvlan、Pipework、Flannel、Weave等。虽然这些方案在实现细节上存在很多差异,但其思路无非分为两种:二层VLAN网络和Overlay网络。
简单来说,二层VLAN网络的解决跨主机通信的思路是把原先的网络架构改造为互通的大二层网络,通过特定网络设备直接路由,实现容器点到点的之间通信。这种方案在传输效率上比Overlay网络占优,然而它也存在一些固有的问题。
这种方法需要二层网络设备支持,通用性和灵活性不如后者;由于通常交换机可用的VLAN数量都在4000个左右,这会对容器集群规模造成限制,远远不能满足公有云或大型私有云的部署需求;大型数据中心部署VLAN,会导致任何一个VLAN的广播数据会在整个数据中心内泛滥,大量消耗网络带宽,带来维护的困难。
相比之下,Overlay网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在IP报文之上的新的数据格式。这样不但能够充分利用成熟的IP路由协议进程数据分发,而且在Overlay技术中采用扩展的隔离标识位数,能够突破VLAN的4000数量限制,支持高达16M的用户,并在必要时可将广播流量转化为组播流量,避免广播数据泛滥。因此,Overlay网络实际上是目前最主流的容器跨节点数据传输和路由方案。
在Docker的1.9中版本中正式加入了官方支持的跨节点通信解决方案,而这种内置的跨节点通信技术正是使用了Overlay网络的方法。
说到Overlay网络,许多人的第一反应便是:低效,这种认识其实是带有偏见的。Overlay网络的实现方式可以有许多种,其中IETF(国际互联网工程任务组)制定了三种Overlay的实现标准,分别是:虚拟可扩展LAN(VXLAN)、采用通用路由封装的网络虚拟化(NVGRE)和无状态传输协议(SST),其中以VXLAN的支持厂商最为雄厚,可以说是Overlay网络的事实标准。
而在这三种标准以外还有许多不成标准的Overlay通信协议,例如Weave、Flannel、Calico等工具都包含了一套自定义的Overlay网络协议(Flannel也支持VXLAN模式),这些自定义的网络协议的通信效率远远低于IETF的标准协议[5],但由于他们使用起来十分方便,一直被广泛的采用而造成了大家普遍认为Overlay网络效率低下的印象。然而,根据网上的一些测试数据来看,采用VXLAN的网络的传输速率与二层VLAN网络是基本相当的。
解除了这些顾虑后,一个好消息是,Docker内置的Overlay网络是采用IETF标准的VXLAN方式,并且是VXLAN中普遍认为最适合大规模的云计算虚拟化环境的SDN Controller模式。
到目前为止一切都是那么美好,大家是不是想动手尝试一下了呢?
且慢,待我先稍泼些冷水。在许多的报道中只是简单的提到,这一特性的关键就是Docker新增的『overlay』类型网卡,只需要用户用『docker networkcreate』命令创建网卡时指定『–driver=overlay』参数就可以。看起来就像这样:
$ docker network create –driver=overlay ovr0
但现实的情况是,直到目前为止,Docker的Overlay网络功能与其Swarm集群是紧密整合的,因此为了使用Docker的内置跨节点通信功能,最简单的方式就是采纳Swarm作为集群的解决方案。这也是为什么Docker 1.9会与Swarm1.0同时发布,并标志着Swarm已经Product-Ready。此外,还有一些附加的条件:
所有Swarm节点的Linux系统内核版本不低于3.16需要一个额外的配置存储服务,例如Consul、Etcd或ZooKeeper所有的节点都能够正常连接到配置存储服务的IP和端口所有节点运行的Docker后台进程需要使用『–cluster-store』和『-–cluster-advertise』参数指定所使用的配置存储服务地址
关于使用 Overlay 网络的设置,稍后在继续介绍 swarm的用法。
推荐相关文档:
- Docker的安装
- Docker的配置文件 daemon.json 详细解
- Docker的启动参数
- Docker的命令之概述
- Docker的命令之容器管理 Container
- Docker的命令之镜像管理 Image
- Docker的命令之网络管理 network
- Docker的命令之集群节点管理 Swarm node
- Docker的命令之插件管理 Plugin
- Docker的命令之安全管理 Docker secret
- Docker的命令之集群服务管理 Service
- Docker的命令之 Docker stacks
- Docker的命令之集群管理 swarm
- Docker的命令之系统管理 Docker system
- Docker的命令之数据卷管理 Volume
- Docker的命令之快捷指令
- Docker中的镜像构建-Dockerfile指令详解
- Docker的实践笔记
- Docker create / Docker run 的选项详解
Pingback引用通告: Docker的命令之网络管理 network | 精彩每一天